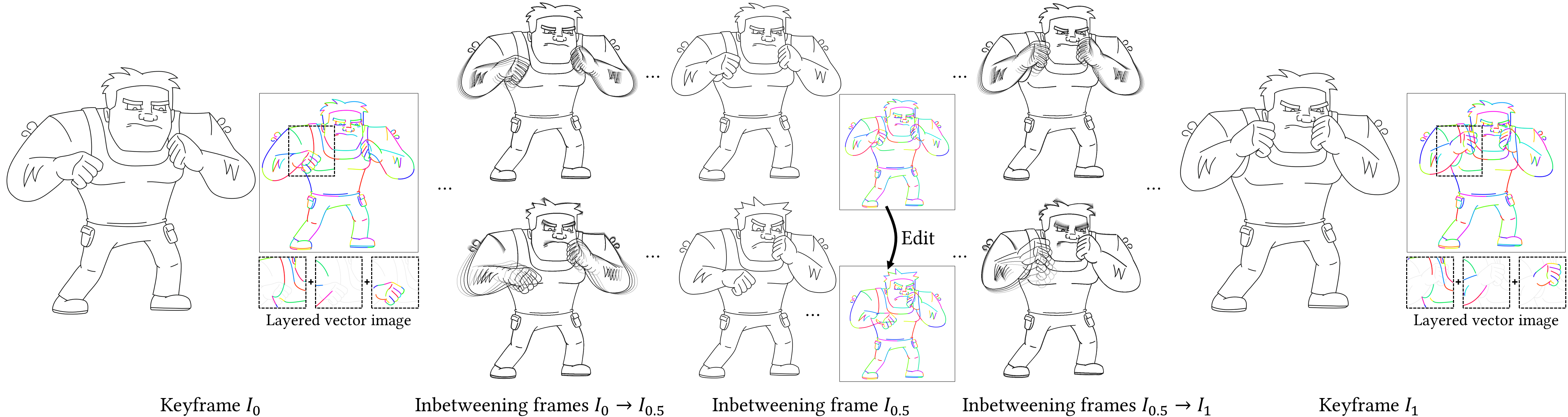
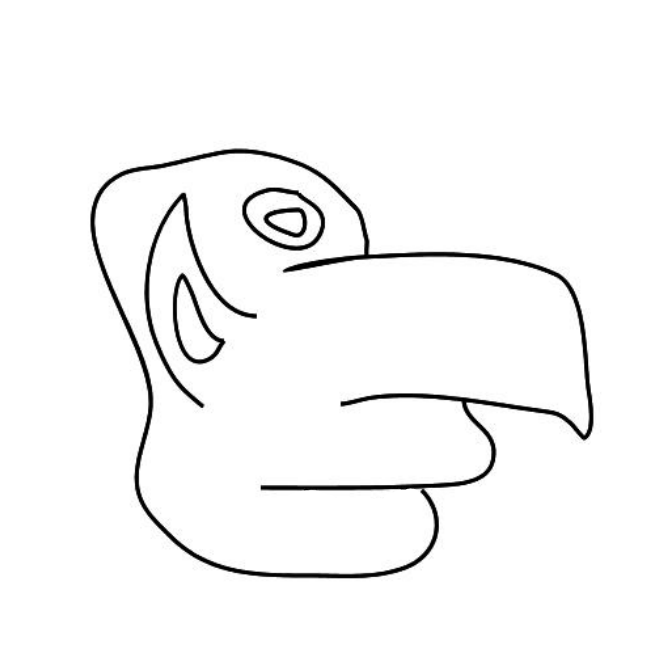
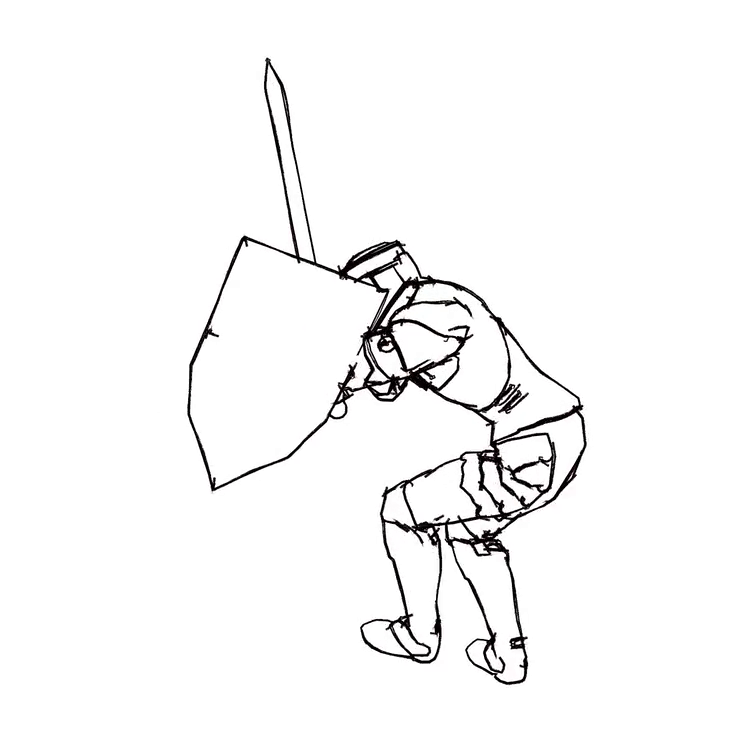
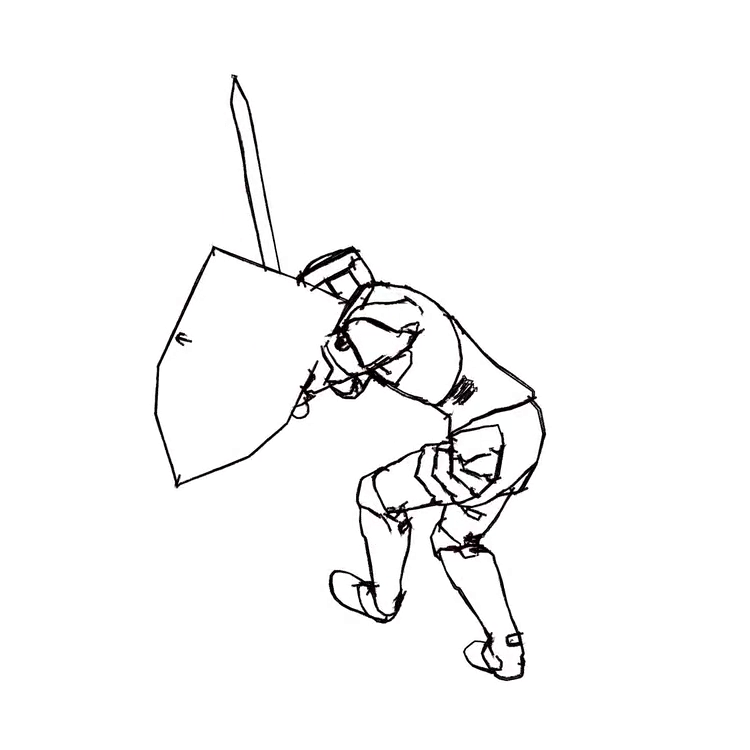
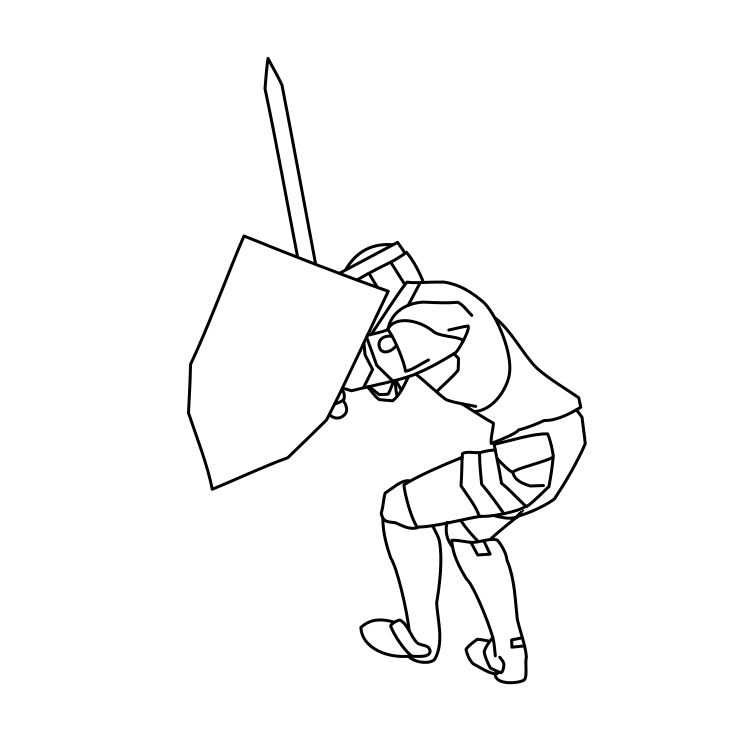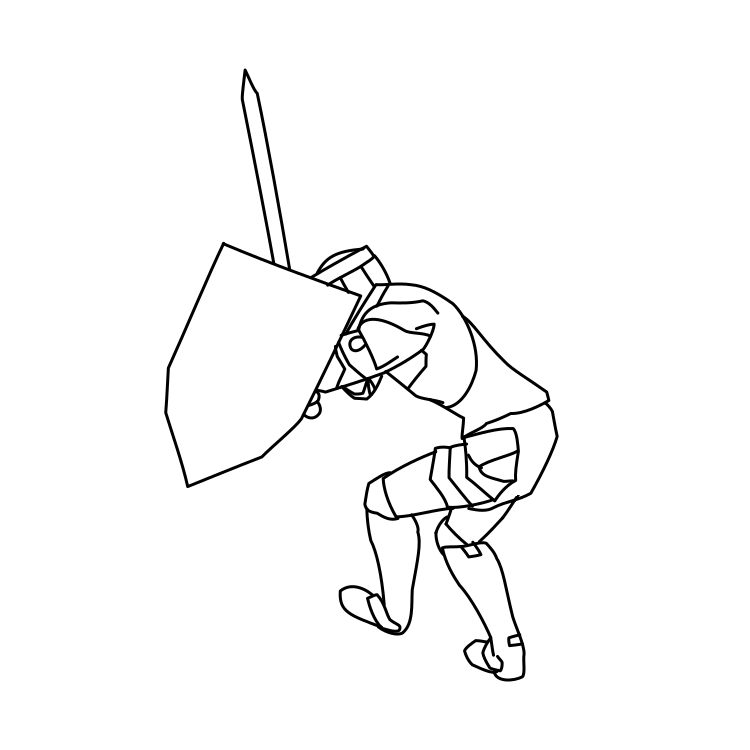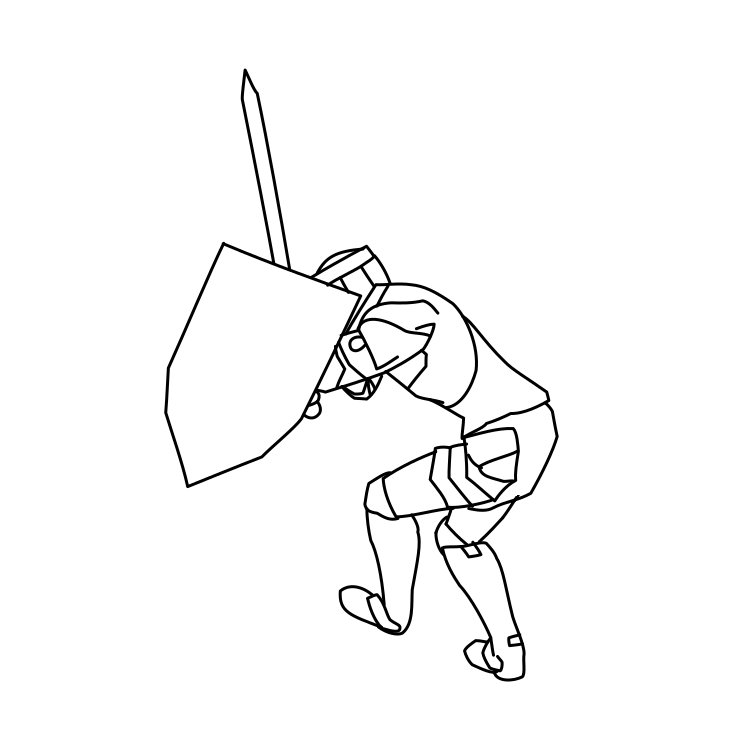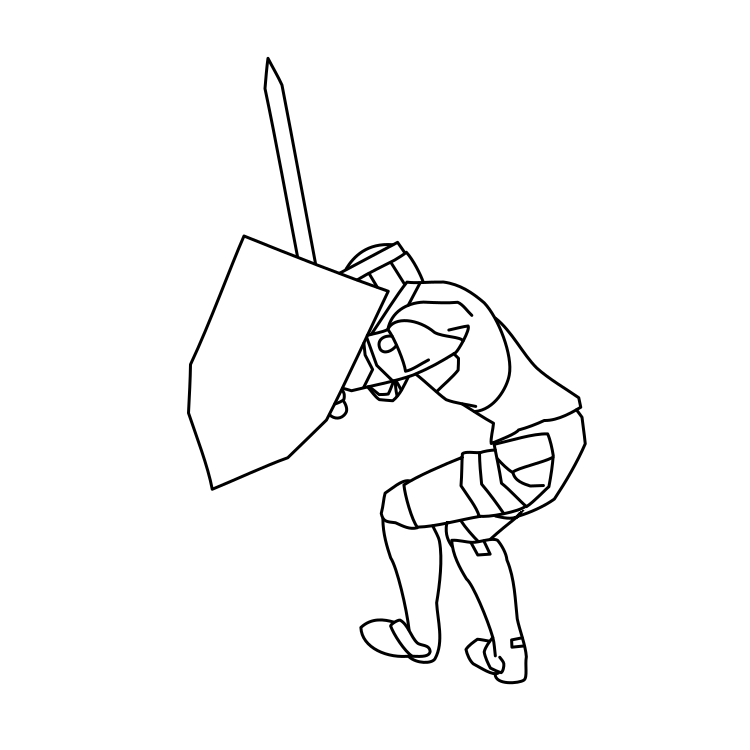
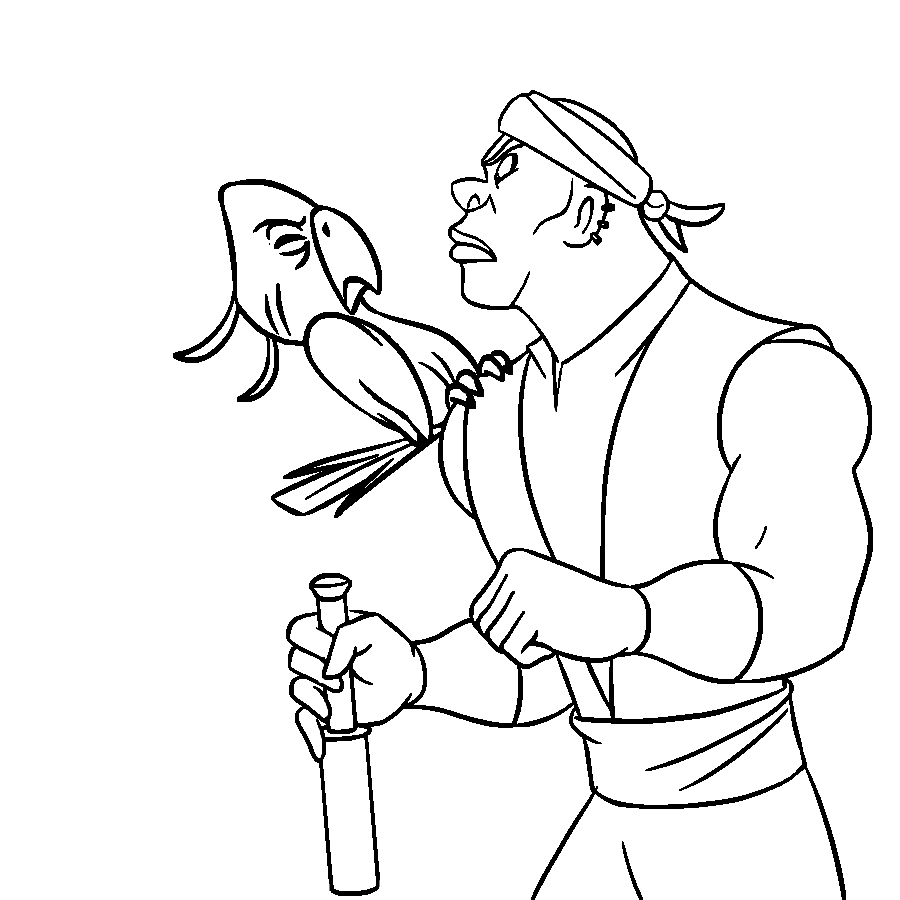
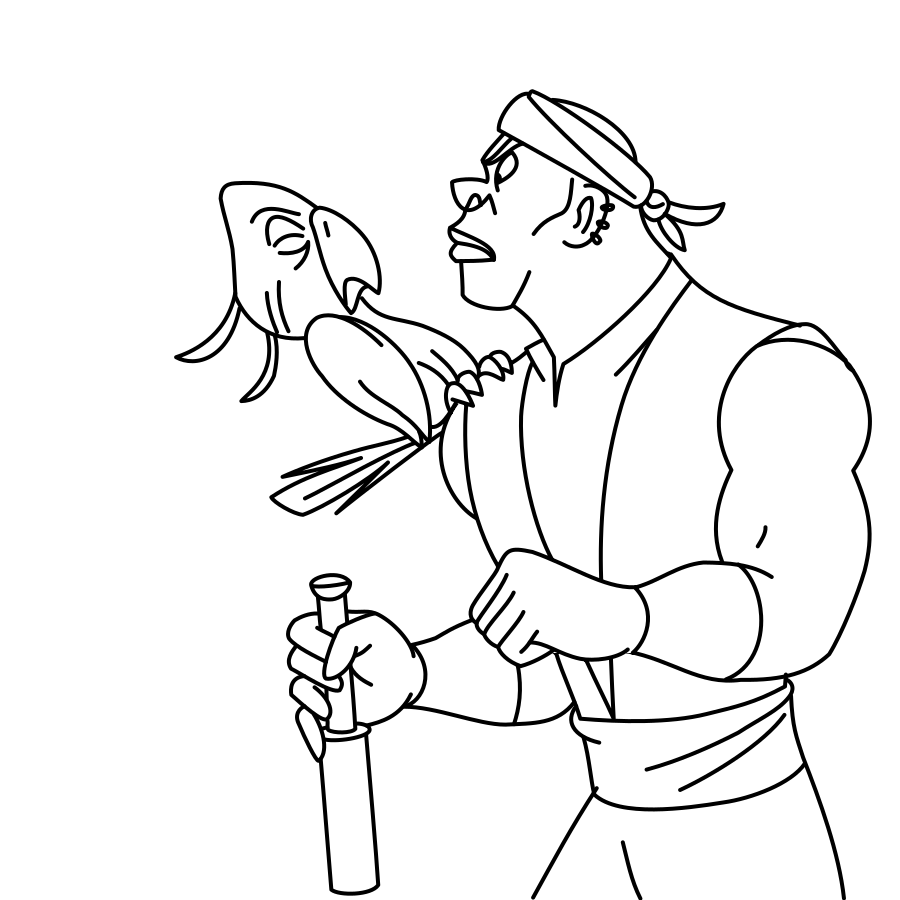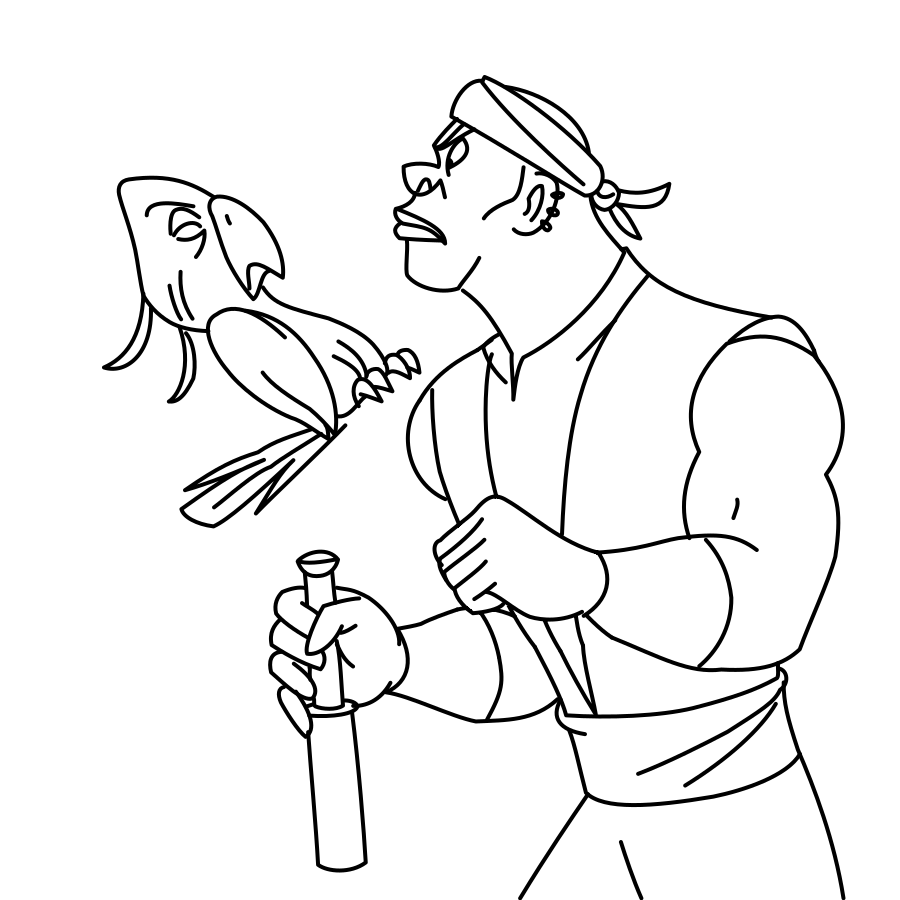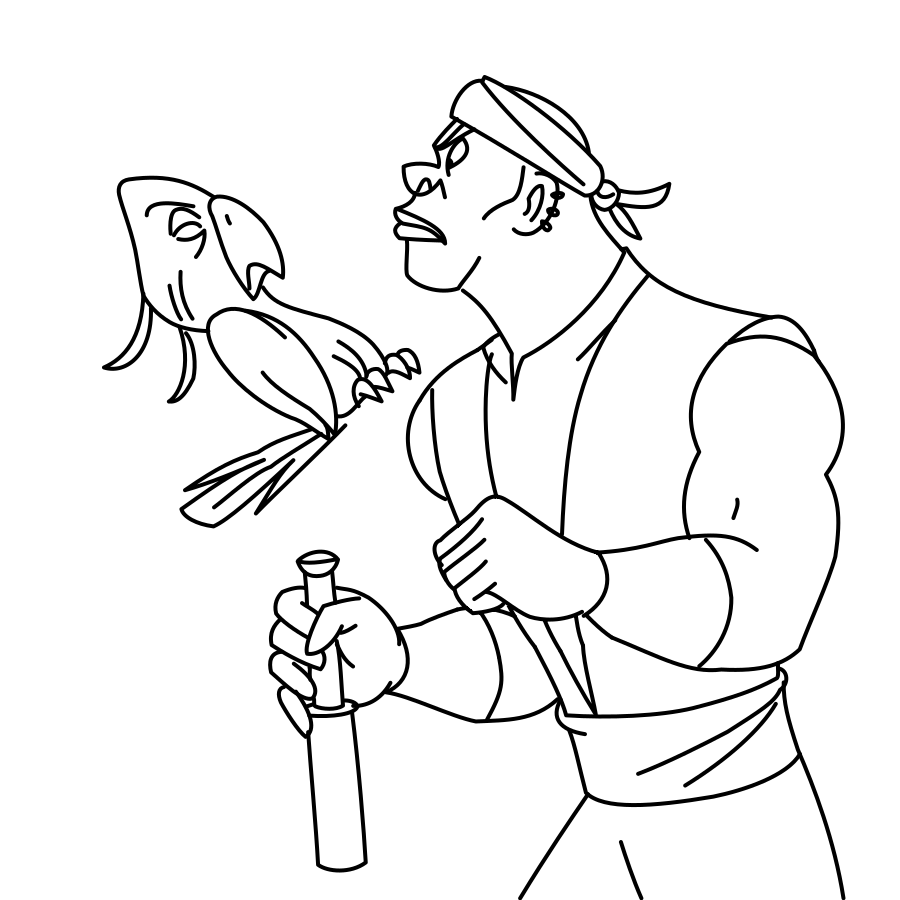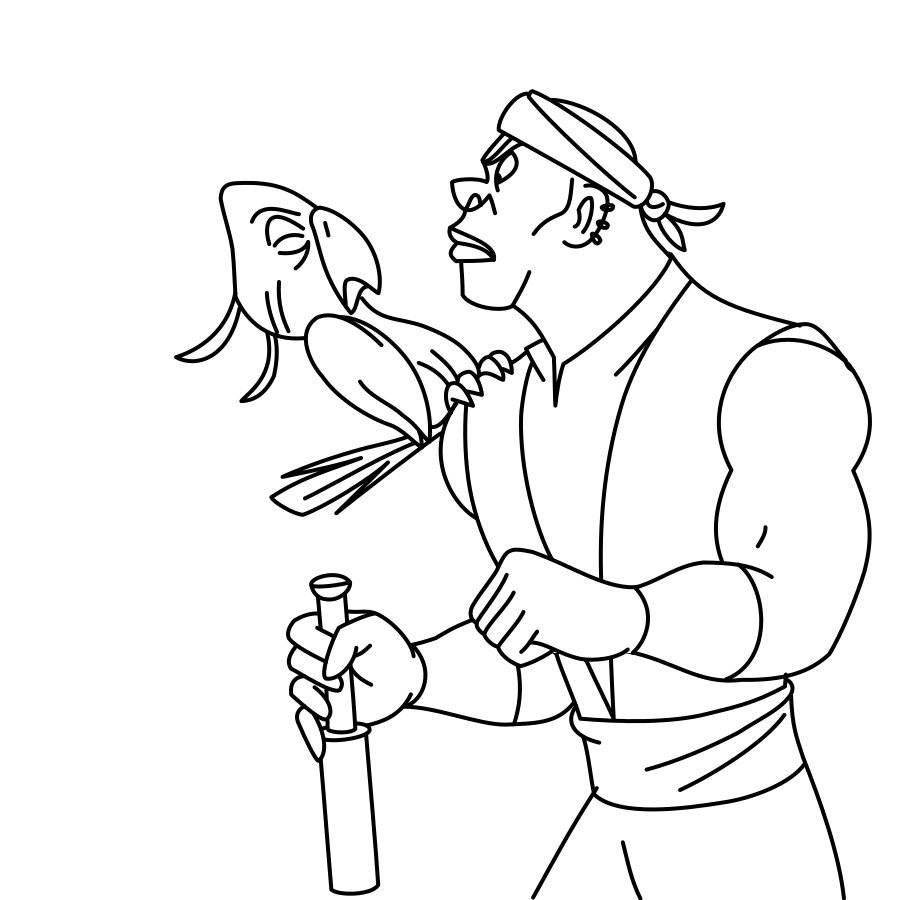
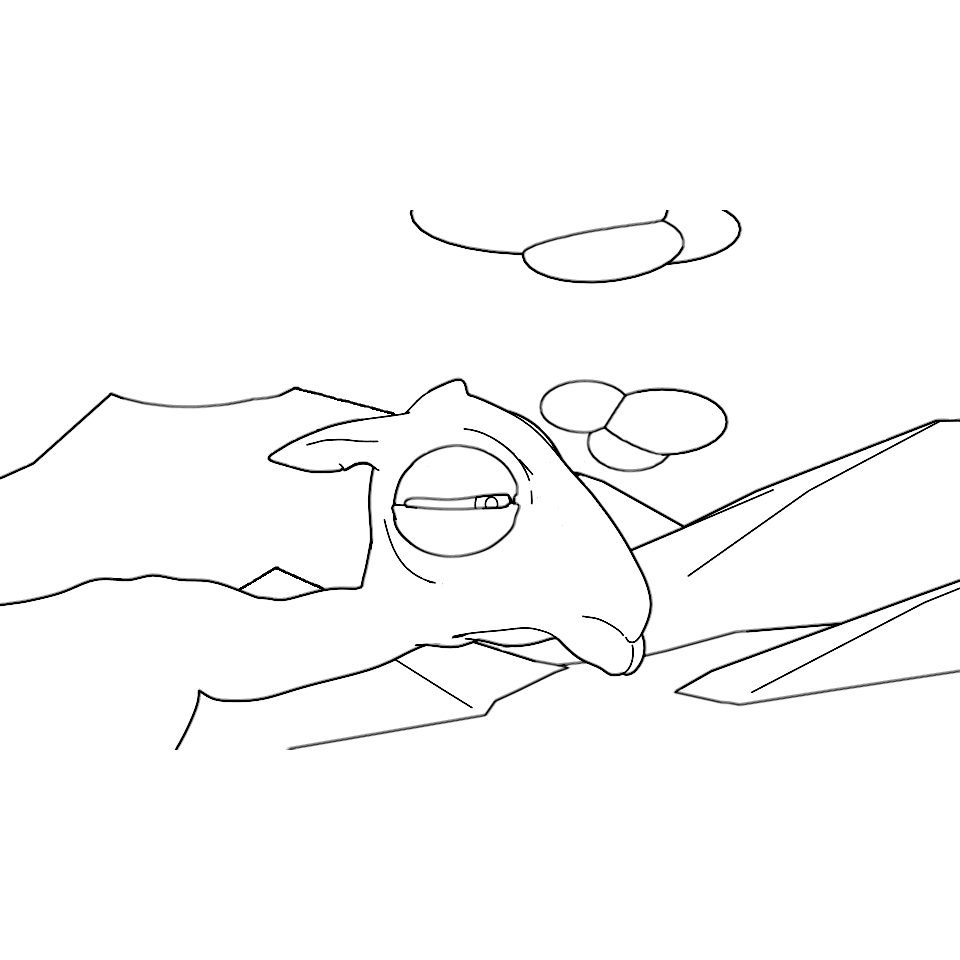
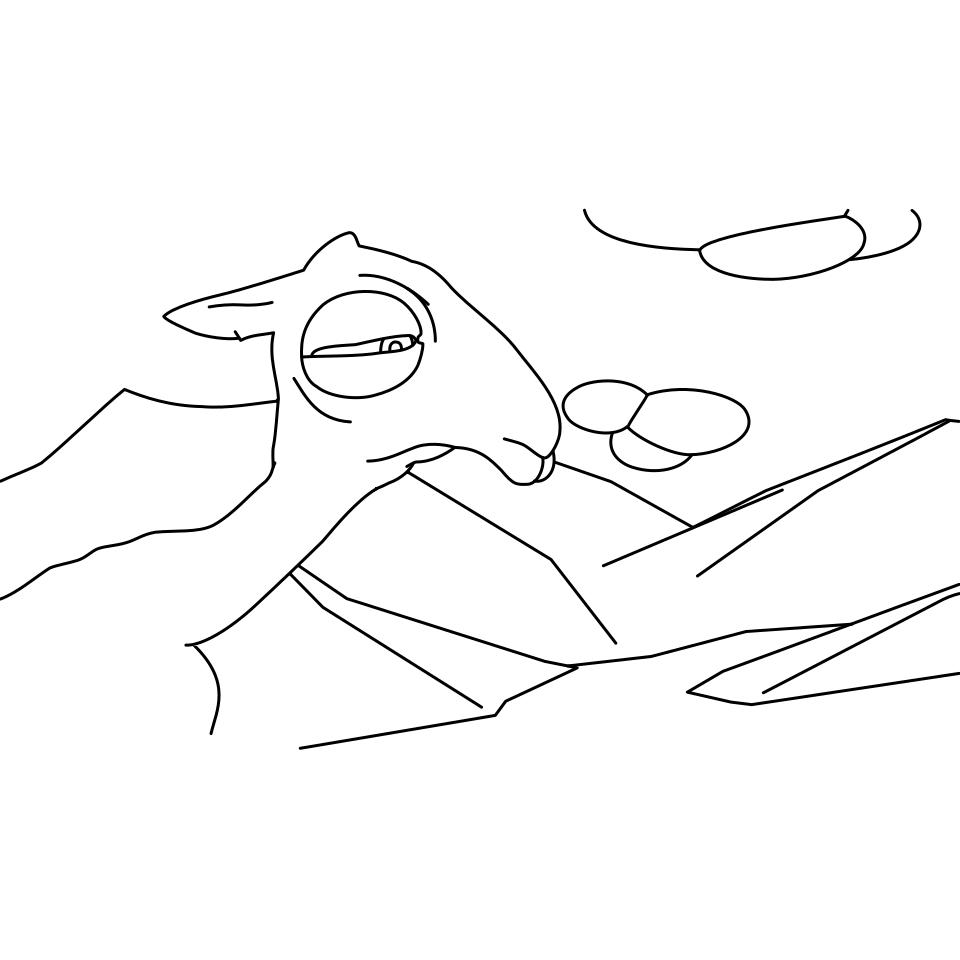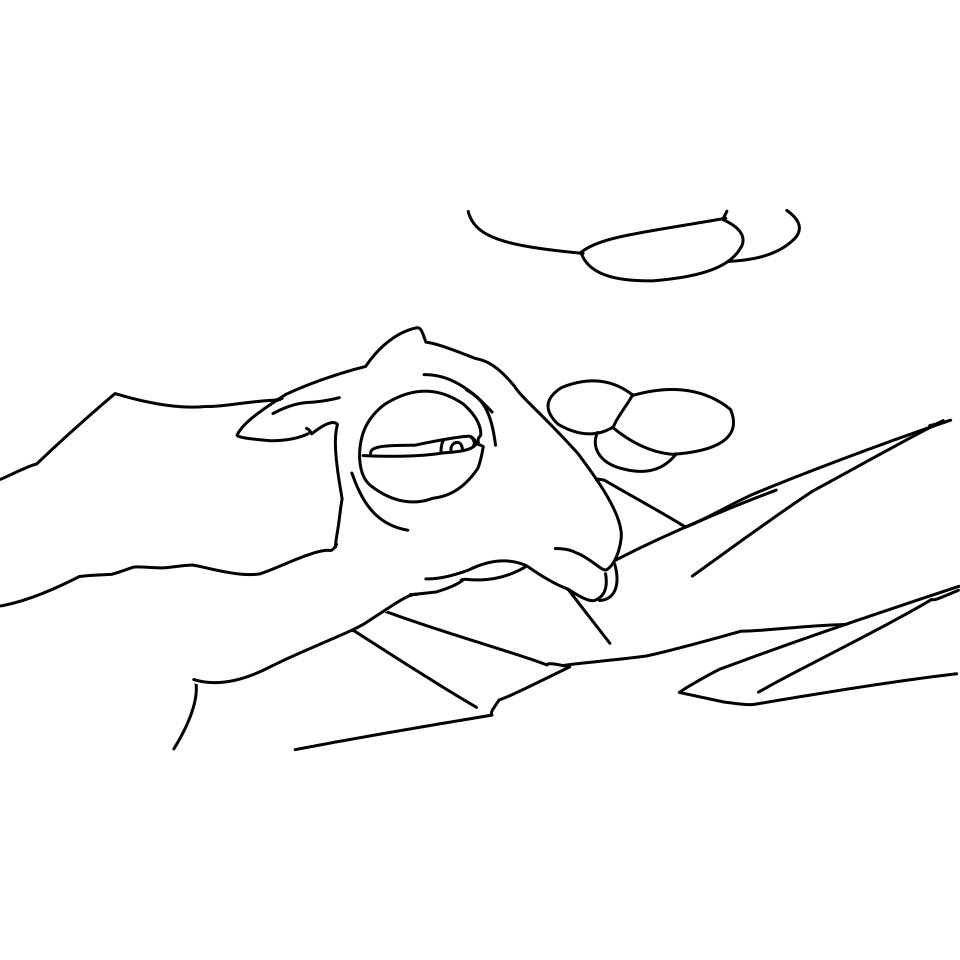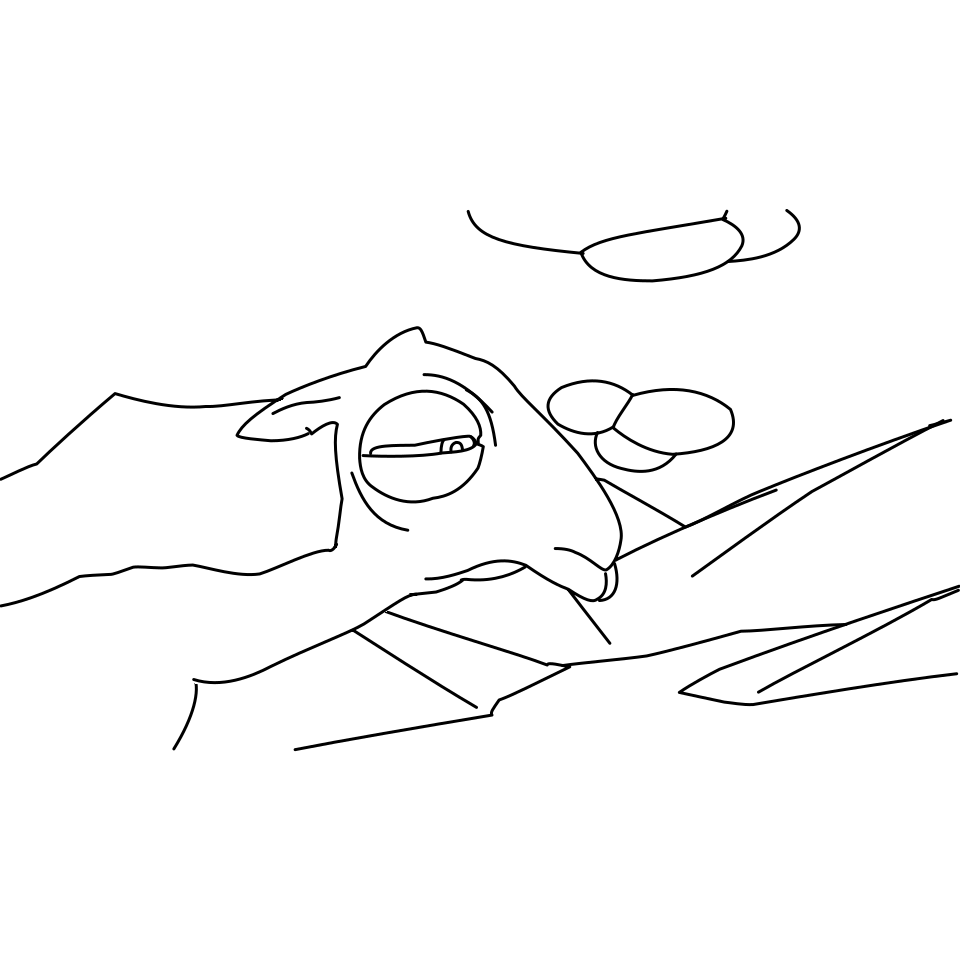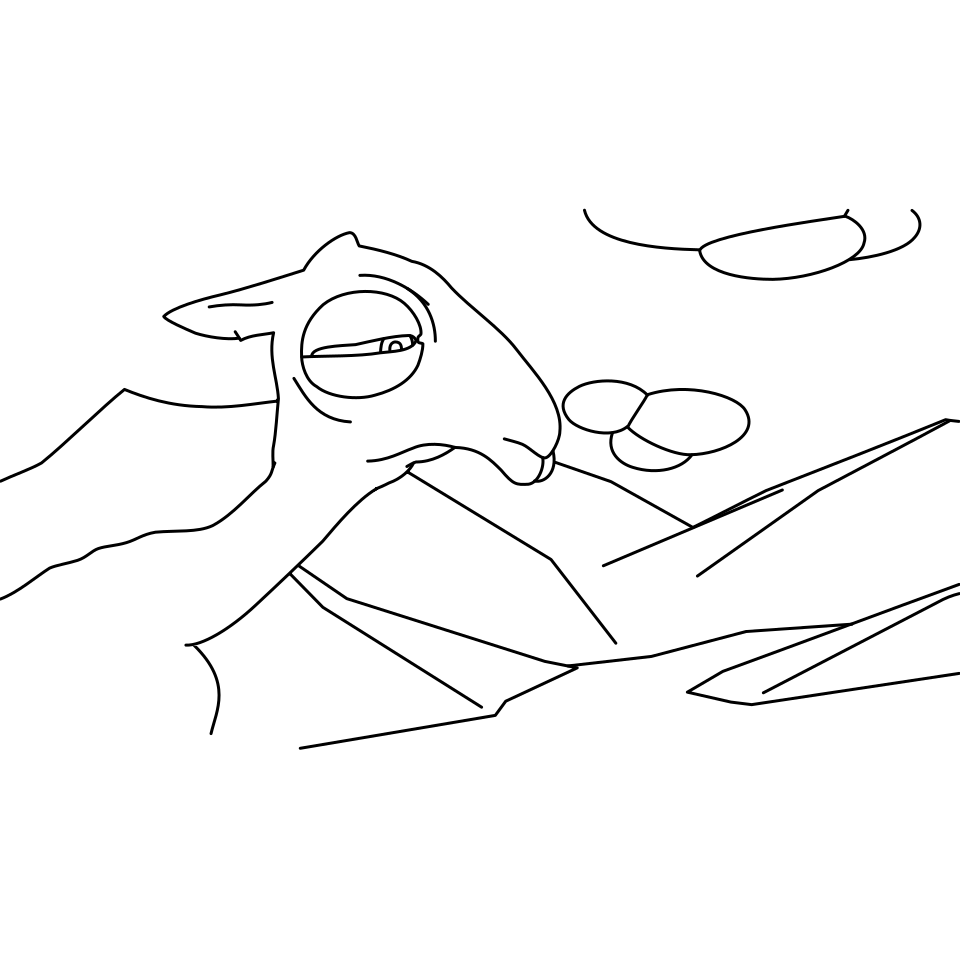
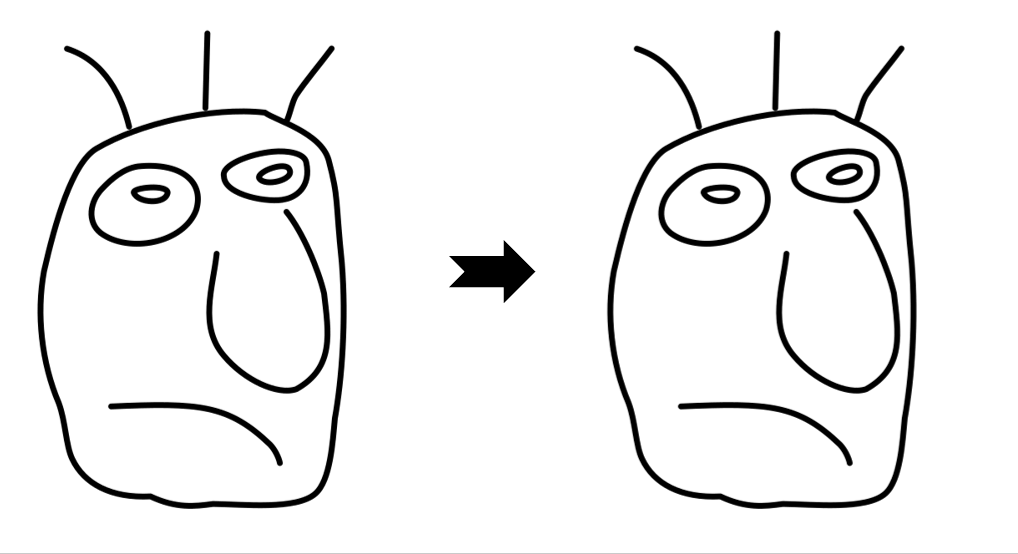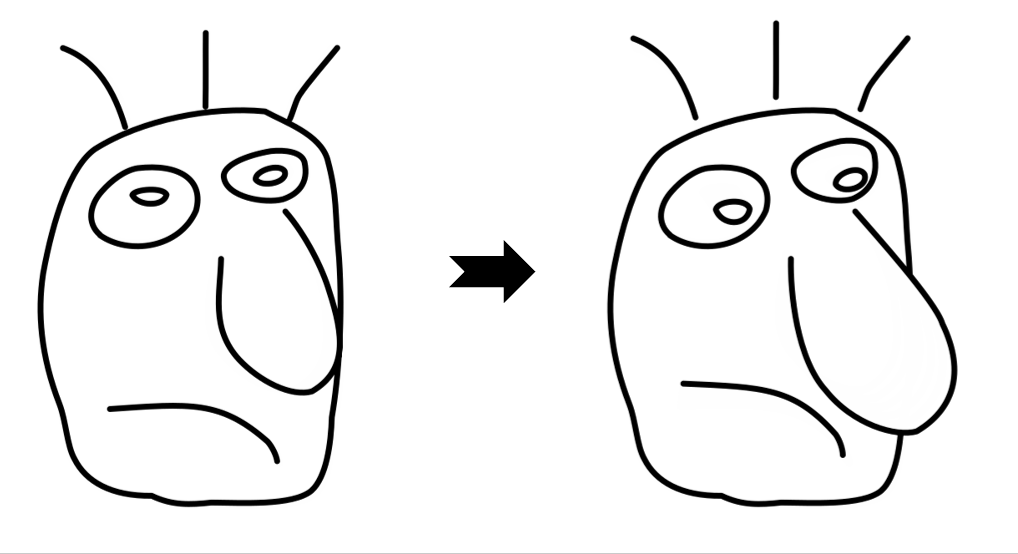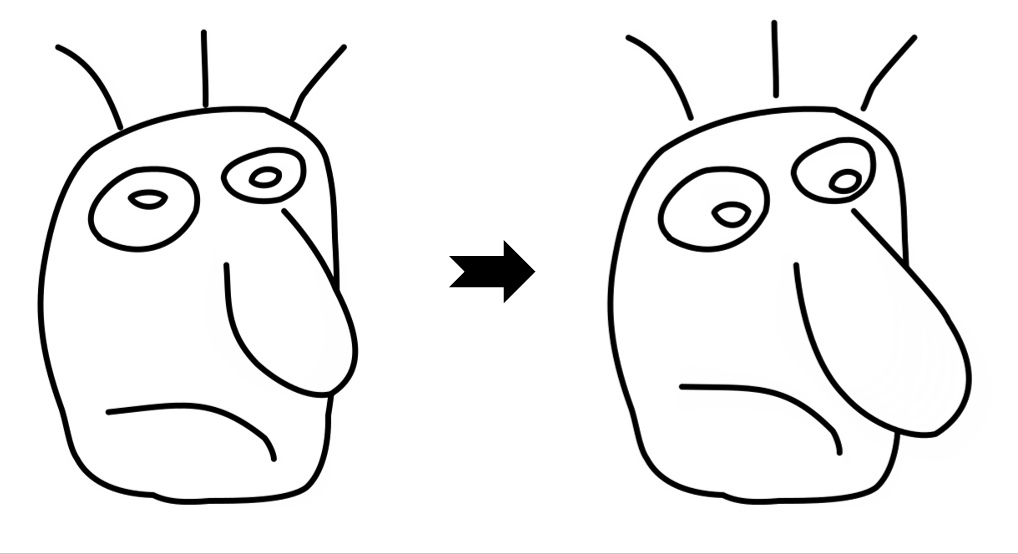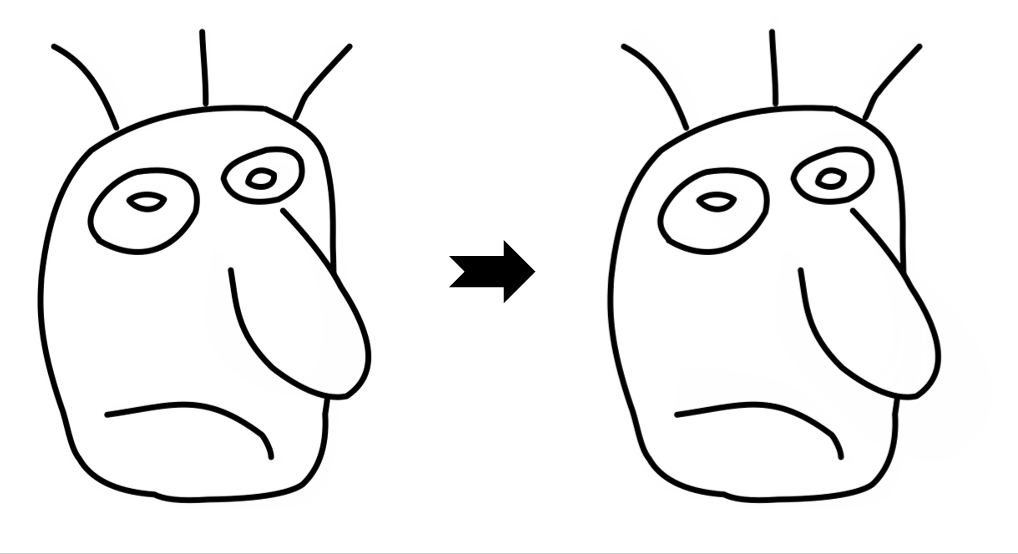
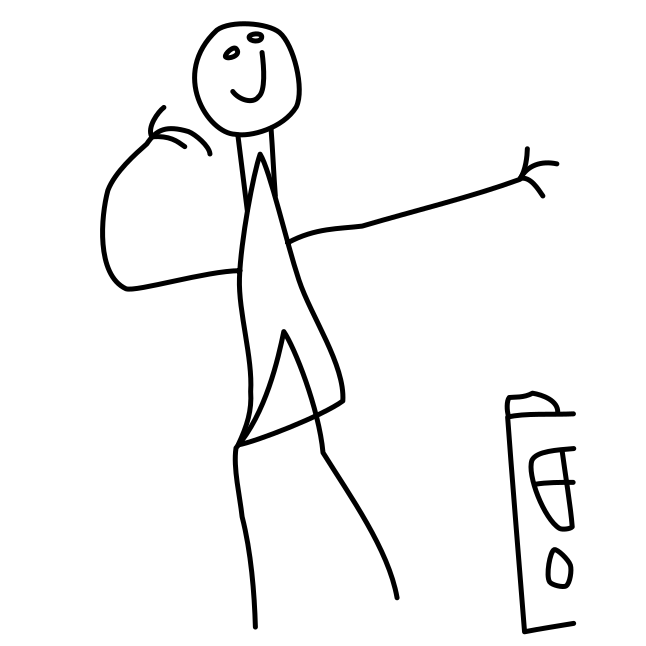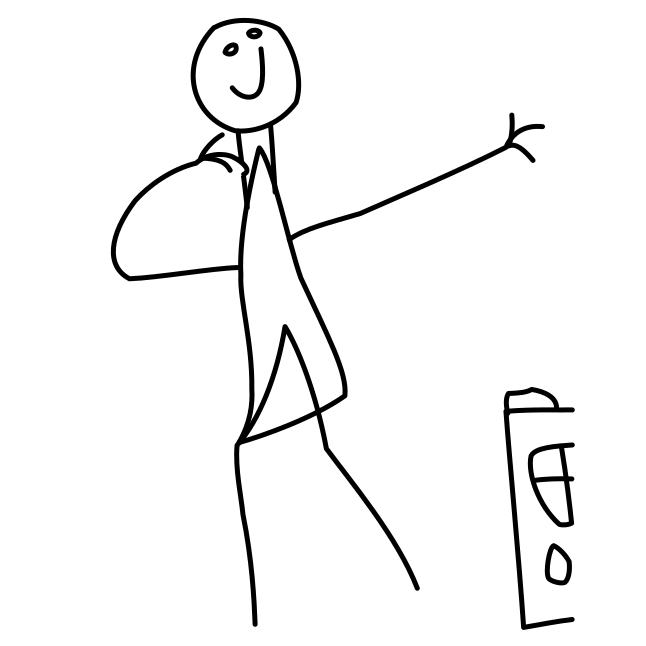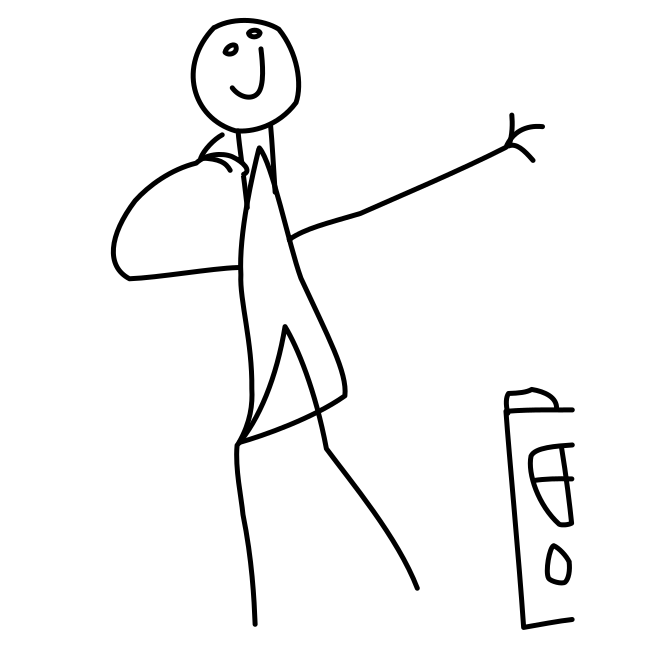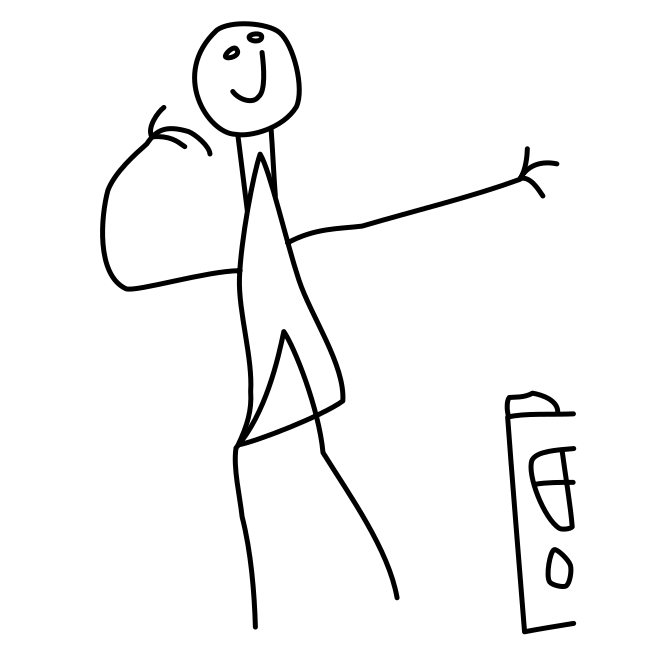Overview of LayerInbetween. Our framework predicts layered vector images for the input raster keyframes with one-to-one correspondences for visible
and especially occluded strokes, which are used to produce inbetweening frames via stroke interpolation. Layers are predicted from the strokes to resolve
occlusion during inbetweening. Our vector-based approach can facilitate convenient inbetweening editing. Raster keyframes are from Jiang et al. [2022].
Abstract
Establishing one-to-one stroke correspondences is fundamental to vector-based animation inbetweening. Animators may face great challenges when handling occlusion, as occluded strokes must be drawn explicitly in keyframes and manually hidden frame by frame after stroke interpolation. To reduce tedious effort, we present LayerInbetween, an occlusion-aware framework for vector stroke correspondence and automatic inbetweening. It performs automatic layering to guide stroke tracing and correspondence finding for occluded strokes, and to resolve occlusion with layers in the inbetween frames. To predict occluded strokes, we propose a Global-Local Layer Transformation (GLLT) module that progressively improves the spatial alignment of strokes across keyframes via layer guidance, thereby indicating their potential positions. Our framework is trained on a synthetic dataset comprising 17k+ pairs of keyframes with occlusion and their stroke correspondences. Extensive experiments demonstrate the effectiveness of LayerInbetween compared with existing methods and its generalization capabilities to various types of drawings. In addition to its superior performance, our vector-based inbetweening method enables more flexible editing of 2D animation than raster-based video generation.
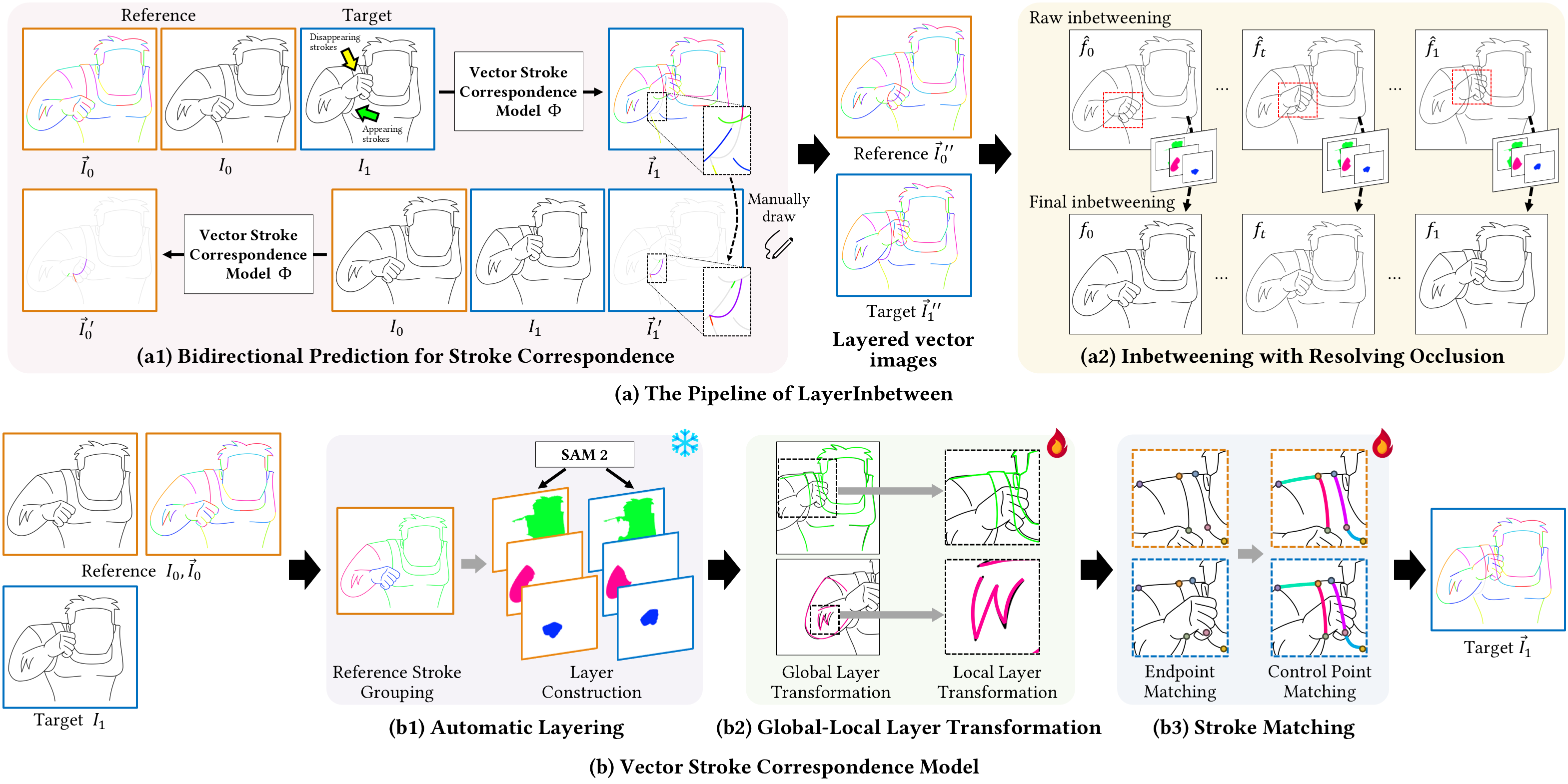
Illustration of the framework of LayerInbetween. (a) It achieves vector stroke correspondence for visible and occluded strokes and automatic inbetweening
with occlusion resolving via layering. (b) The vector stroke correspondence model comprises an automatic layering step to construct stroke groups with regions
and a stacking order, a Global-Local Layer Transformation (GLLT) module to improve stroke alignment between keyframes using layer guidance, and a stroke
matching step to predict the corresponding strokes in the target frame.
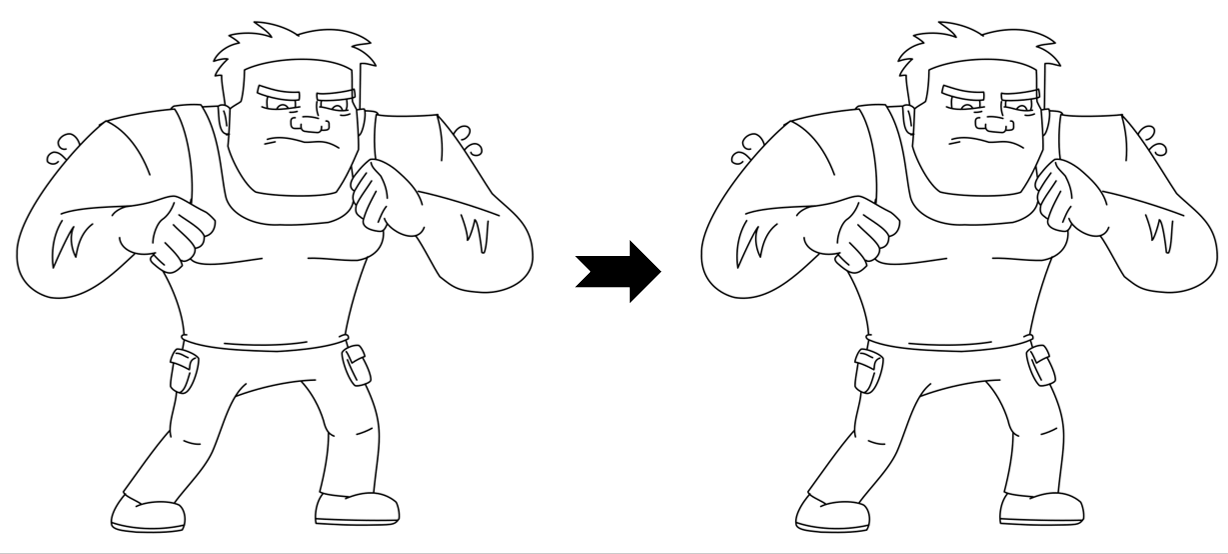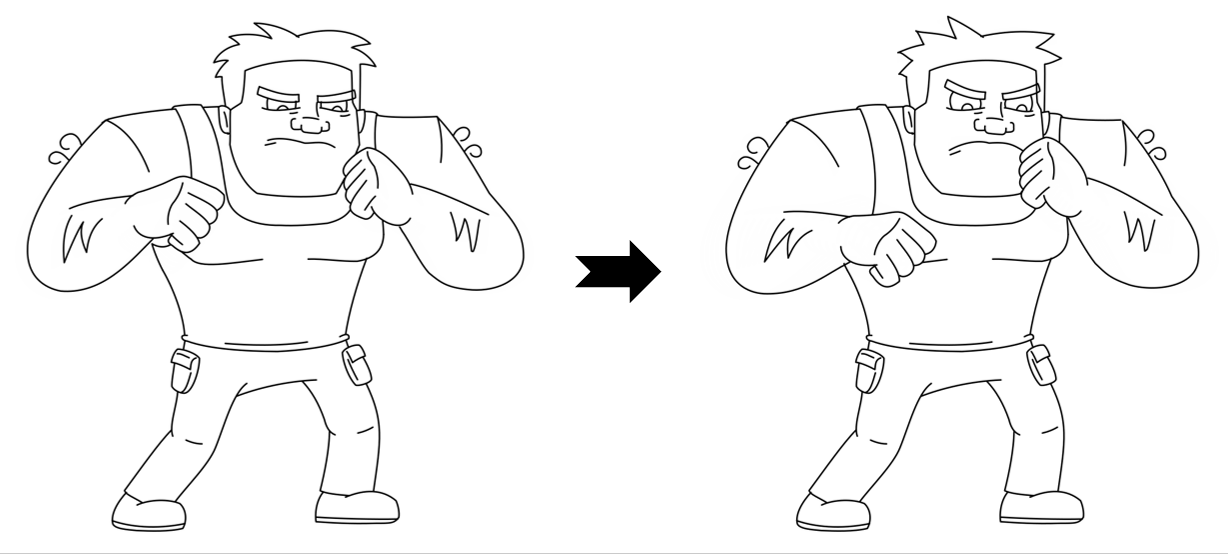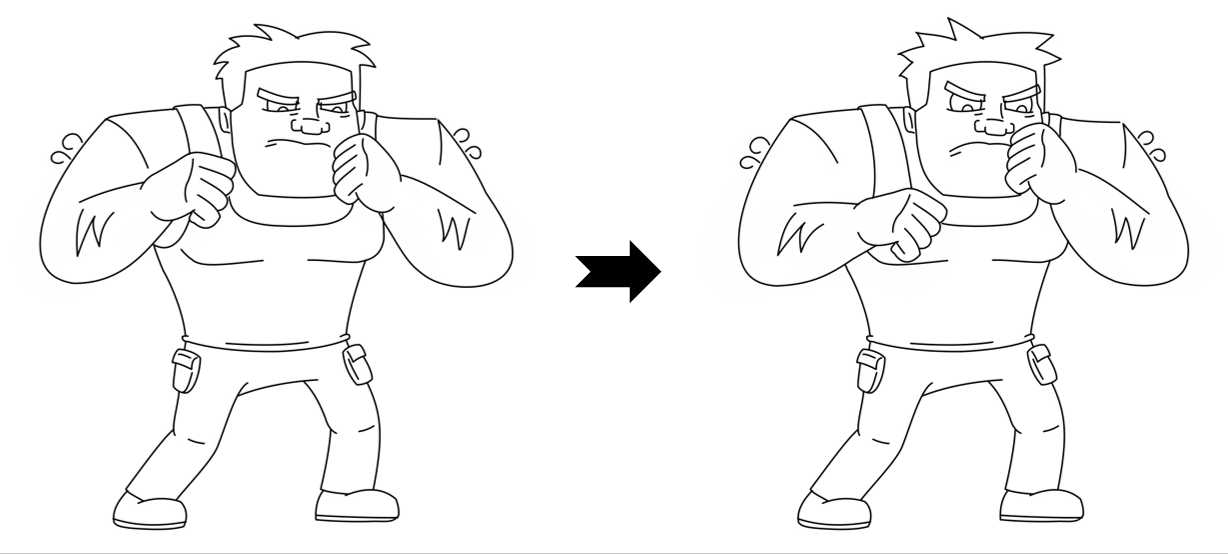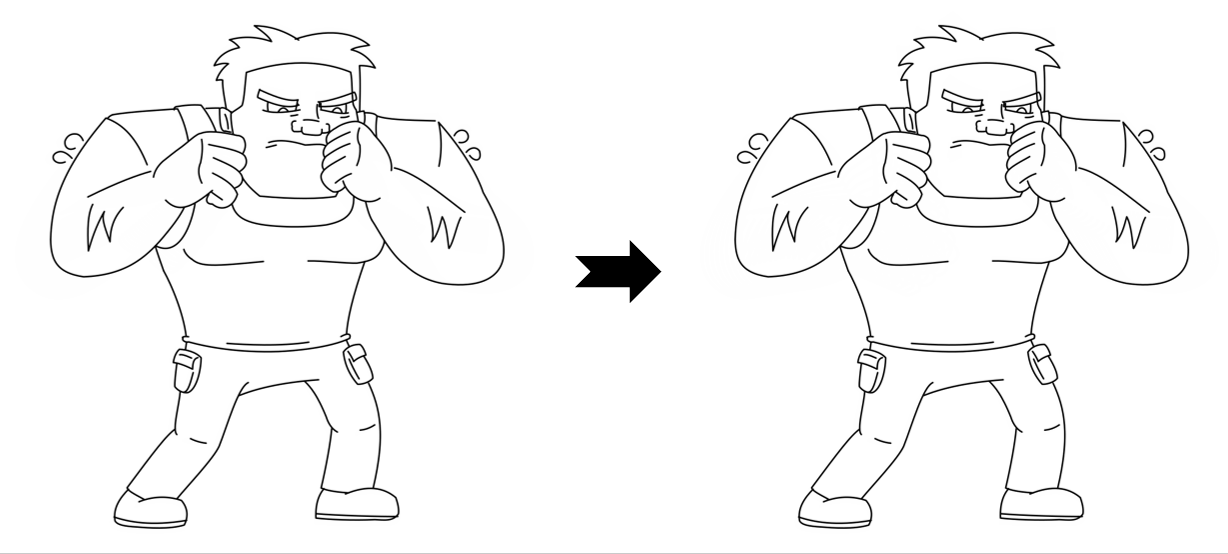
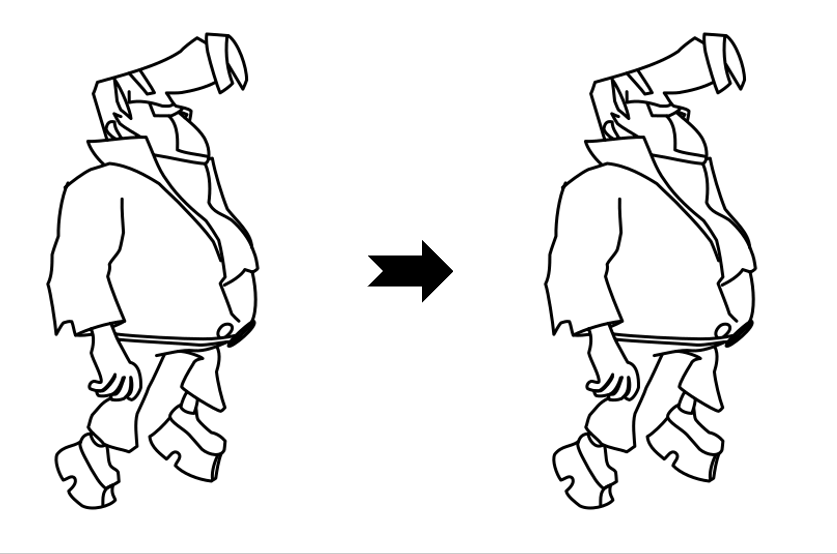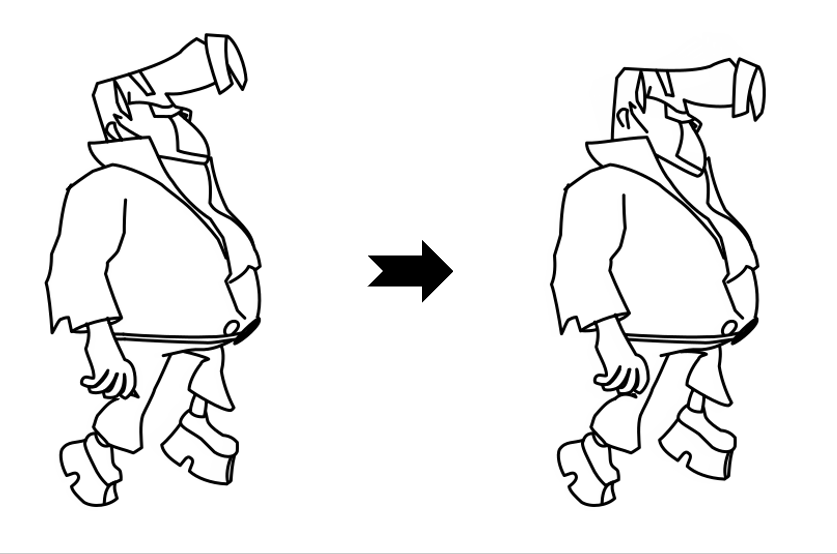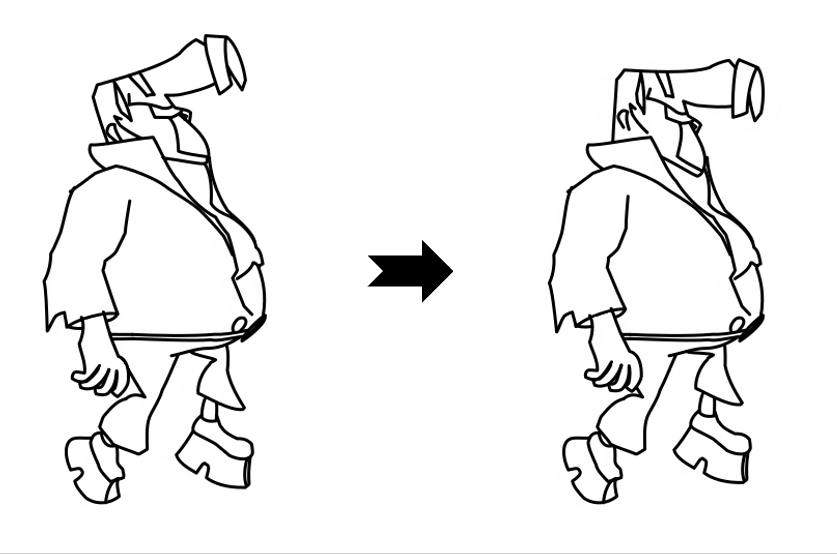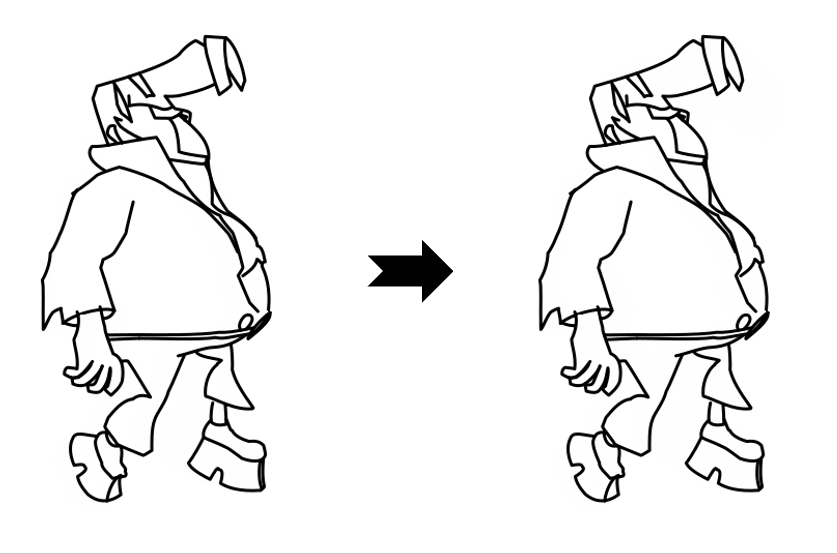
Results
While LayerInbetween is trained with clean single-character line art pairs,
it generalizes well to rough sketches , multi-character line art, complex scenes,
abstract drawings, and multi-keyframe sequences.
@article{mo2026layerinbetween,
title = {LayerInbetween: Occlusion-Aware Stroke Correspondence and Inbetweening with Automatic Layering},
author = {Mo, Haoran and Guan, Zhongyue and Hu, Yixin and Wang, Zeyu},
journal = {ACM Transactions on Graphics (TOG)},
year = {2026},
volume = {45},
number = {4},
pages = {1--17},
publisher={ACM New York, NY}
}